This is the third and forth week(17-21st June) of the coding period of GSoC where the main aim was to configure different existing extractors and mappings for Hindi.
Table of Contents
Open Table of Contents
Extractor configuration
I have configured several extractors, discussed below, with some of the code changes:
-
RedirectExtractor: For managing redirects.
-
HomepageExtractor: To extract homepage URLs.
private val propertyNamesMap = Map( #..., + "hi" -> Set("वेबसाइट"), # Homepage in hindi #..., ) private val externalLinkSectionsMap = Map( # ..., + "hi" -> "बाहरी कड़ियाँ", # External Link in hindi # ..., ) -
DisambiguationExtractor: For handling disambiguation pages.
val NonFreeRegex = Map( #..., + "hi" -> " (बहुविकल्पी)", // eg. https://hi.wikipedia.org/wiki/आयरलैण्ड_(बहुविकल्पी) #..., ) -
TopicalConceptsExtractor: To identify and extract topical concepts.
-
ImageExtractorNew: To handle image extraction.
val NonFreeRegex = Map( #..., + "hi" -> """(?i)\{\{\s?non-free""".r, #..., ) -
Added Mappings for Different Infoboxes. Mappings for various infoboxes have been added, enhancing our ability to organize and categorize the data effectively.
-
Moreover the coverage of entities also increased from 60% to 70%.
Before
 After
After
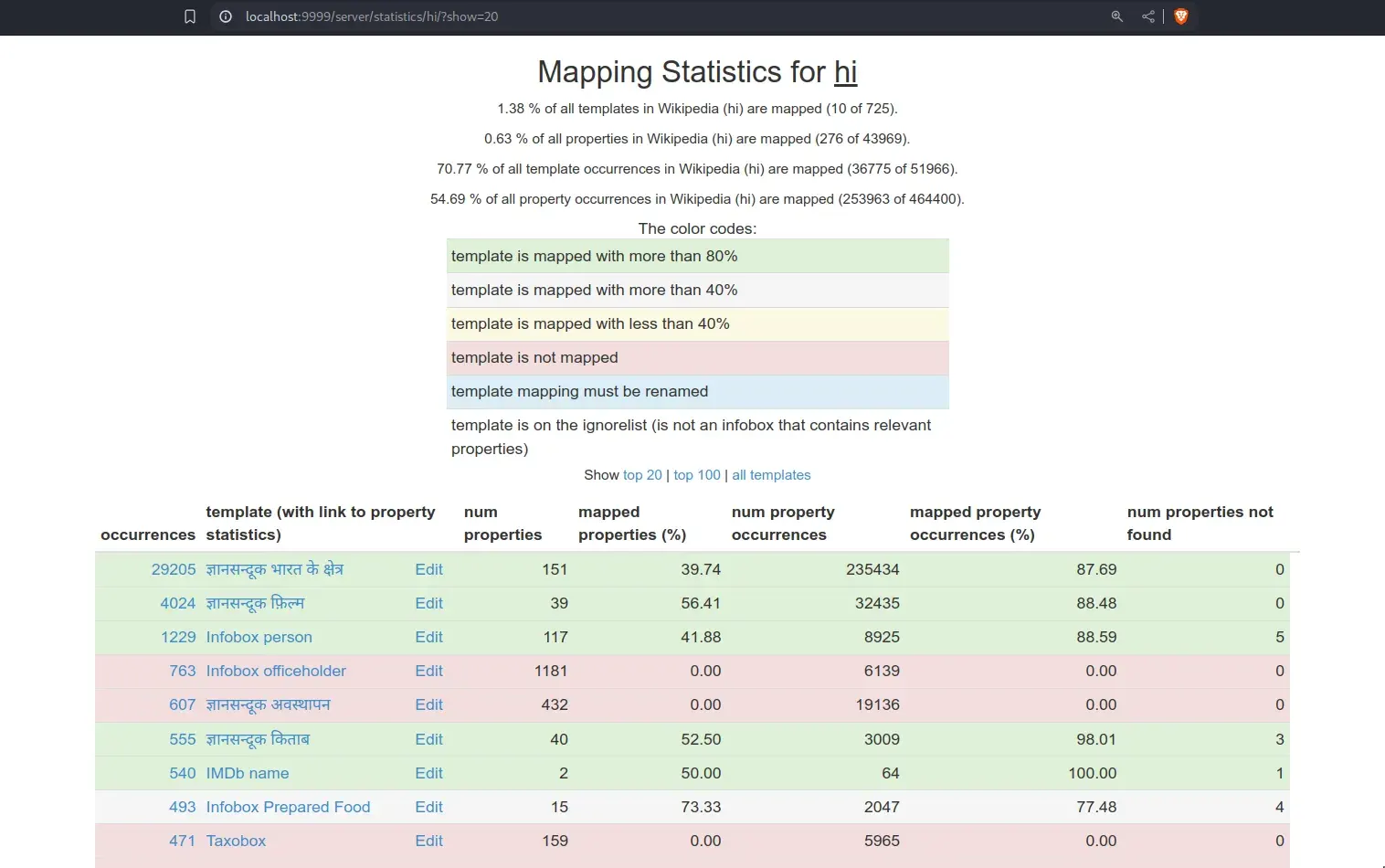
All the extractors are also added to the properties file.
extractors.hi=.MappingExtractor,.HomepageExtractor,.DisambiguationExtractor,.TopicalConceptsExtractor,.ImageExtractorNew,.AnchorTextExtractor,.CommonsResourceExtractor
Learning and Next Steps
-
Challenges in Server Setup for Viewing Statistics: I encountered an issue with setting up the server to view statistics. However, this challenge was swiftly resolved with the assistance of another GSoC contributor, Meti. Collaborating on this solution has been a great example of teamwork and mutual support.
-
Plan to Configure the Abstract Extractor for Hindi: I aim to configure the abstract extractor to support Hindi. This will involve tailoring the extractor to handle the nuances of the Hindi language.
-
Increase Mapping Coverage of Hindi Mappings: In line with our mentors’ suggestions, I will work on manually adding mappings to increase the Hindi coverage. This will be a significant step towards enhancing the inclusivity and richness of our dataset.