This is the fifth and sixth week(24-28th June & 1-5th July) of the coding period of GSoC where the main aim was to increase the mapping coverage of Hindi Chapter.
Table of Contents
Open Table of Contents
Updates in Extraction Framework
-
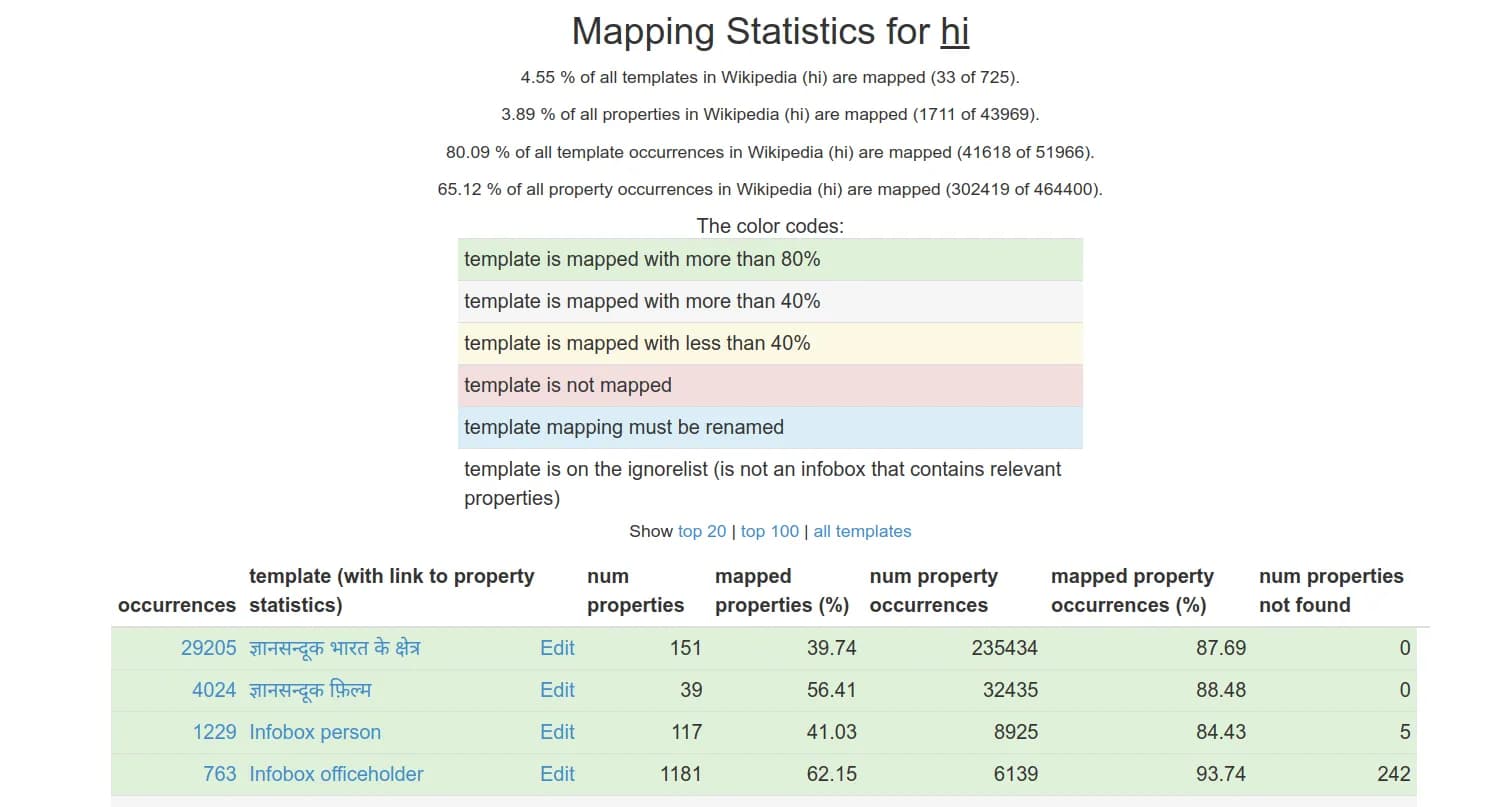
Mapping Update This week, we made significant progress with our mappings for the Hindi DBpedia chapter. By manually creating high-quality mappings, we increased the mapping coverage from 60% to 80%. This improvement is a major step towards achieving comprehensive and accurate data representation.
-
Abstract Extractor I successfully configured the Abstract Extractor for the Hindi language. This enhancement will allow us to effectively generate abstracts for Hindi entries, enriching our dataset with summarized information.
-
Date-interval Extractor Updated the present/now mapping of Wikipedia to incorporate the changes for Hindi Wikipedia.
val presentMap = Map( # ..., + "hi" -> Set("अबतक"), # ..., ) -
Date-time Parser config I configured the parser mapping for date and time from hindi wiki.
val monthsMap = Map( # ..., + "hi" -> Map("जनवरी"->1, "फरवरी"->2, "मार्च"->3, "अप्रैल"->4, "मई"->5, "जून"->6, "जुलाई"->7, "अगस्त"->8, "सितम्बर"->9, "अक्टूबर"->10, "नवंबर"->11, "दिसंबर"->12), # ..., ) val eraStrMap = Map( # ..., + "hi" -> Map("ई\\.पू\\." -> -1, "BC" -> -1, "ई॰" -> 1, "CE"-> 1, "AD"-> 1, "AC"-> -1), # ..., ) -
Duration Parser I configured the duration(sec/min/Yr/etc.) parser for Hindi.
val timesMap = Map( # ..., + "hi" -> Map( + "सेकेंड" -> "second", + "सेकेण्ड" -> "second", + "s" -> "second", + "\"" -> "second", + "मिनट" -> "minute", + "\’" -> "minute", + "m" -> "minute", + "घंटा" -> "hour", + "दिन" -> "day", + "महीना" -> "month", + "वर्ष" -> "year", + ), # ..., )
Challenges and Solutions
1. Extraction Framework Issues We faced an issue running the extraction framework on my local system. The solution to this problem involves gaining server access, which our mentors have agreed to provide. This will help us bypass local system limitations and ensure smooth operations.
2. Neural Extraction Framework Implementation The implementation details of the neural extraction framework remain unclear. Our mentors need to discuss this further with Tomaso to gain a better understanding and proceed with the implementation.
Next Steps
1. Deploy RDFs on a Server We will work on deploying the RDFs on a server to make them accessible to all users. This step is crucial for ensuring that our data can be utilized effectively by the community.
2. Setup the SPARQL Endpoint Setting up the SPARQL endpoint on a server is a priority. This will enable users to perform complex queries and retrieve precise information from our dataset.
That’s all for this week’s update. We’re making great strides and are eager to continue building on our progress. Stay tuned for more updates!