In the past few weeks, I’ve have contributed to the Extraction framework of DBpedia which focused on using infoboxes. But as the infoboxes in Hindi Wikipedia have either very less information or none atall(see below for comparison), thus neural extraction becomes very important.
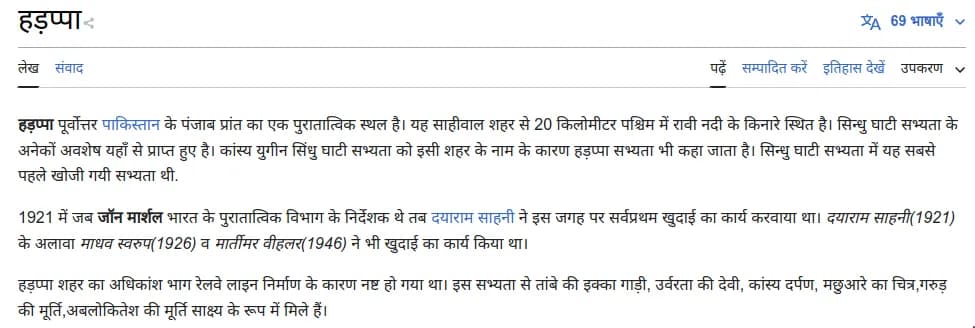
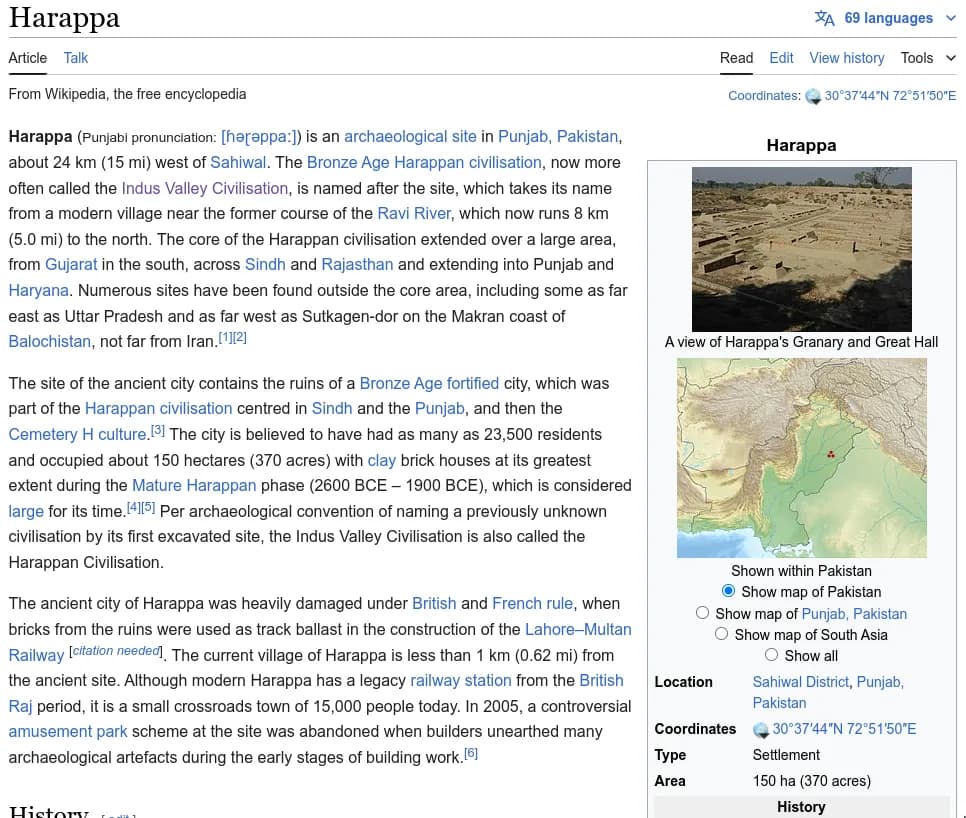 Thus in the seventh and eighth week(8-19th July) of the coding period of GSoC my main aim was to start experimenting the Neural Extraction pipeline of Hindi Wikipedia.
Thus in the seventh and eighth week(8-19th July) of the coding period of GSoC my main aim was to start experimenting the Neural Extraction pipeline of Hindi Wikipedia.
Table of Contents
Open Table of Contents
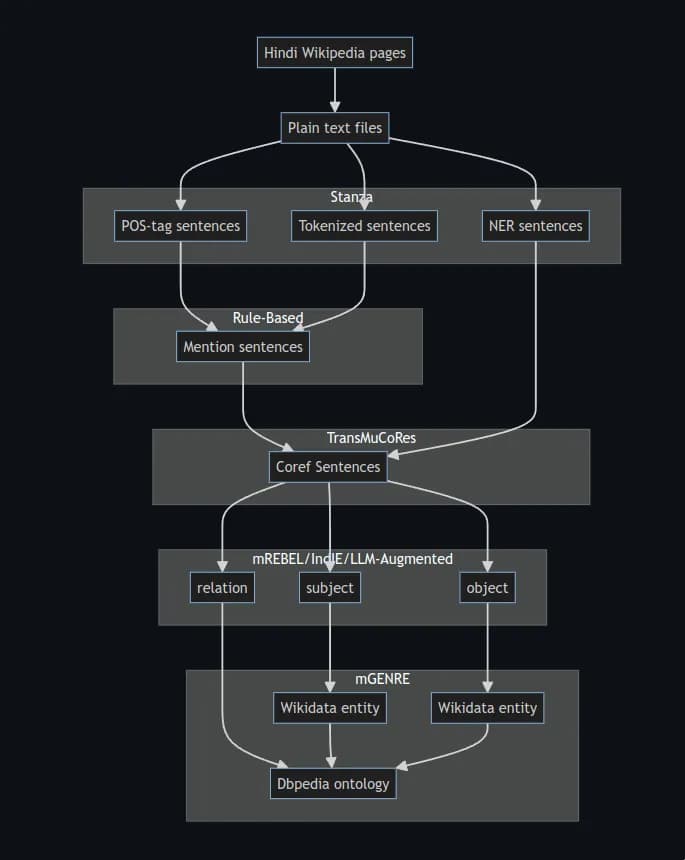
Pipeline overview
The expected pipeline for processing Hindi Wikipedia pages into structured data involves several key steps, each leveraging different tools and models. Here’s a brief explanation of the process:
-
Hindi Wikipedia Pages to Plain Text Files: The pipeline begins by converting Hindi Wikipedia pages into plain text files, which serve as the raw data for further processing.
-
Tokenization, POS Tagging, and NER:
- Tokenization: The sentences from the text files are tokenized using the Stanza library, breaking down the text into individual words or tokens.
- POS Tagging: The tokenized sentences are then POS-tagged using Stanza to identify the grammatical parts of speech (e.g., nouns, verbs) for each token.
- NER Tagging: Named Entity Recognition (NER) is performed using the IndicNER model to identify and classify named entities (e.g., people, locations, organizations) within the text.
-
Mention Detection: Sentences with mentions (i.e., entities that need to be tracked across the text) are identified by combining the results from POS tagging and tokenization in a rule-based manner.
-
Coreference Resolution: Coreference resolution is applied using the TransMuCoRes model to link mentions of the same entity across different parts of the text, creating a unified representation of each entity.
-
Triple Extraction (Subject, Relation, Object): From the coreference-resolved sentences, subject, relation, and object triples are extracted using mREBEL, IndIE, or LLM-augmented models. These triples represent the relationships between entities within the text.
-
Entity Linking and Ontology Mapping:
- The extracted subjects and objects are linked to their corresponding Wikidata entities using the mGENRE model.
- The relations are mapped to the DBpedia ontology, which standardizes the relationships within the knowledge graph.
-
Final Integration: The linked entities and mapped relations are integrated into a coherent structure, creating a rich, interconnected dataset that can be used for various applications.
This pipeline efficiently converts unstructured text from Hindi Wikipedia into structured knowledge, ready for inclusion in DBpedia KG.
Project Update
In this two weeks, i focused on developing some components of the pipeline:
- Processed Hindi Wikipedia Articles: The articles were first scraped from wikipedia and then converted into .txt format for easy processing.
- Tokenization with Stanza Library: I used the Stanza library to tokenize the sentences, which is a crucial step before any further linguistic analysis.
- POS Tagging: Stanza was also employed to find the Part-of-Speech (POS) tags, helping in understanding the grammatical structure of the sentences.
- NER Tagging with IndicNER Model: Named Entity Recognition (NER) tags were extracted using the IndicNER model, which is tailored for Indian languages.
- Relation Extraction: Lastly, I used a rule-based model to extract relationships between the entities, adding another layer of understanding to the data.
Challenges/Solutions
During the implementation, I encountered some hurdles and how I’m planning to address them using the below ways:
-
LLM-Based Approaches Not Tried: Although I was keen to explore LLM-based approaches, I couldn’t deploy them on my local system due to technical limitations.
-
Suggestions from Mentors: My mentors recommended using LLMstudio or Ollama to deploy LLMs locally. This advice is invaluable, and I’m eager to put it into practice.
Next Steps
Looking ahead, I have some clear action items that I’ll be focusing on:
-
Try LLM-Based Coreference Resolution: I plan to experiment with LLMs for coreference resolution, which will help in identifying and linking entities within the text.
-
Try LLM-Based Relation Extraction: Building on the coreference resolution, I’ll also explore LLM-based methods for relation extraction to enhance the accuracy and depth of the information extracted.
The upcoming weeks will be crucial as I dive into these LLM-based approaches, and I’m excited about the potential advancements they could bring to the project.